安装前准备
准备安装包
安装包清单:
jdk: jdk-8u65-linux-x64.gz
hadoop: hadoop-3.1.1.tar.gz
mysql:
mysql80-community-release-el7-1.noarch.rpm
mysql-connector-java-8.0.12-1.el7.noarch.rpm
hive: apache-hive-3.1.0-bin.tar.gz
准备部署环境
当前测试基于三个节点组成的集群环境,iP分别为:10.10.20.38, 10.10.20.39, 10.10.20.40
其中:
10.10.20.40: 为hadoop主节点,并部署hive和mysql
10.10.20.38, 10.10.20.39: 为Hadoop数据节点
部署jdk
分发jdk压缩包
拷贝jdk压缩包到集群内所有服务器指定路径下(当前测试是基于/home/soft),解压缩jdk包,并部署到/home/jdk1.8.0_65目录下
1 2 3 4 5 6 [root@gis040 ~]# cd /home/soft [root@gis040 soft]# tar -zxvf jdk-8u65-linux-x64.gz -C /home [root@gis040 soft]# cd .. [root@gis040 home]# cd jdk1.8.0_65/ [root@gis040 jdk1.8 .0 _65]# pwd /home/jdk1.8 .0 _65
复制pwd生成的结果路径,配置java环境变量
1 2 3 4 5 6 7 8 [root@gis040 jdk1.8.0_65]# vim /etc/profile Insert 以下内容: export JAVA_HOME =/home/jdk1.8.0_65export CLASS_PATH =.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH =$JAVA_HOME /bin:$PATHesc-> :wq! 退出并保存编辑配置 [root@gis040 jdk1.8.0_65]# source /etc/profile
部署Hadoop集群
创建安装用户
在所有hadoop集群服务器上创建用户hadoop,这里以10.10.20.40服务器为例
1 2 3 4 5 [root@gis040 jdk1.8.0_65]# cd ~ [root@gis040 ~]# adduser hadoop [root@gis040 ~]# passwd hadoop Changing password for user hadoop. New password:
这里密码我设置了hadoop@123
配置集群间ssh免密
这步是必须操作, 集群间ssh免密是通过自动化shell脚本auto_ssh.sh 完成的,需要的同学自行下载。
使用前需要修改:
1 2 3 4 5 [root@gis040 ~] [root@gis040 scripts] IP_1 =10.10 .20.39 ,10.10 .20.38 ,10.10 .20.40 PWD_1 =hadoop@123 USER_1 =hadoop
替换IP_1, PWD_1, USER_1为你部署环境真实hadoop 集群的IP地址,Hadoop用户名密码,和Hadoop用户名
1 [root@gis040 scripts]# ./auto_ssh.sh
部署hadoop压缩包
解压缩部署hadoop:
1 2 3 4 [root@gis040 scripts]# cd .. [root@gis040 soft]# tar -zxvf hadoop-3.1.1.tar.gz -C /home [root@gis040 soft]# cd .. [root@gis040 home]# chown -R hadoop:hadoop hadoop-3.1.1/
配置环境变量:
1 2 3 4 5 [root@gis040 hadoop-3.1.1]# vim /etc/profile export HADOOP_HOME =/home/hadoop-3.1.1export PATH =$PATH :$HADOOP_HOME/bin[root@gis040 jdk1.8.0_65]# source /etc/profile
hadoop参数配置
1 2 3 [root@gis040 home] [hadoop@gis040 home]$ cd hadoop-3.1 .1 / [hadoop@gis040 hadoop-3.1 .1 ]$ cd etc/hadoop/
配置hadoop-env文件:
1 2 3 4 5 [hadoop@gis040 hadoop]$ vim hadoop-env.sh 修改以下内容: export JAVA_HOME =/home/jdk1.8.0_65export HADOOP_HOME =/home/hadoop-3.1.1
配置core-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [hadoop@gis040 hadoop]$ vim core-site.xml <configuration> <property> <name> fs.defaultFS</name> <value> hdfs://10.10.20.40:9000</value> </property> <property> <name> hadoop.proxyuser.hive.groups</name> <value> * </value> </property> <property> <name> hadoop.proxyuser.hive.hosts</name> <value> * </value> </property> </configuration>
配置说明:
10.10.20.40需要替换为你的hadoop主节点地址
hadoop.proxyuser.hive.groups和hadoop.proxyuser.hive.hosts是针对hive的配置项,其中”hive”,对应于你环境下实际的hive用户。
配置hdfs-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [hadoop@gis040 hadoop]$ vim hdfs-site.xml <configuration> <property> <name> dfs.replication</name> <value> 2</value> </property> <property> <name> dfs.namenode.name.dir</name> <value> file:///home/hadoop/dfs/name</value> </property> <property> <name> dfs.datanode.data.dir</name> <value> file:///home/hadoop/dfs/data</value> </property> <property> <name> dfs.namenode.secondary.http-address</name> <value> 10.10.20.40:50090</value> </property> <property> <name> dfs.webhdfs.enabled</name> <value> true</value> </property> <property> <name> dfs.permissions</name> <value> false</value> </property> </configuration>
配置说明:
10.10.20.40需要替换为你的hadoop主节点地址
上述配置中涉及的dir项目需要在你的环境中真实存在,如果没有,可以通过mkdir命令创建, 例如:
1 2 [hadoop@gis 040 hadoop]$ mkdir -p /home/ hadoop/dfs/ name [hadoop@gis 040 hadoop]$ mkdir -p /home/ hadoop/dfs/ data
配置mapreduce-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [hadoop@gis040 hadoop]$ vim mapreduce-site.xml <configuration> <property> <name> mapreduce.framework.name</name> <value> yarn</value> </property> <property> <name> mapreduce.jobhistory.address</name> <value> 10.10 .20 .40 :1002 </value> </property> <property> <name> mapreduce.jobhistroy.webapp.address</name> <value> 10.10 .20 .40 :19888 </value> </property> <property> <name> yarn.app.mapreduce.am.env</name> <value> HADOOP_MAPRED_HOME=/home/ hadoop-3.1 .1 </value> </property> <property> <name> mapreduce.map.env</name> <value> HADOOP_MAPRED_HOME=/home/ hadoop-3.1 .1 </value> </property> <property> <name> mapreduce.reduce.env</name> <value> HADOOP_MAPRED_HOME=/home/ hadoop-3.1 .1 </value> </property> </configuration>
配置说明:
10.10.20.40需要替换为你的hadoop主节点地址
上述配置中yarn.app.mapreduce.am.env, mapreduce.map.env, mapreduce.reduce.env 对于通过hive 调度mapreduce执行任务是否成功至关重要。
配置yarn-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [hadoop@gis040 hadoop]$ vim yarn-site.xml <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.aux-services.mapreduce.shuffle.class</name > <value > org.apache.hadoop.mapred.ShuffleHandler</value > </property > <property > <name > yarn.resourcemanager.address</name > <value > 10.10.20.40:8032</value > </property > <property > <name > yarn.resourcemanager.scheduler.address</name > <value > 10.10.20.40:8030</value > </property > <property > <name > yarn.resourcemanager.admin.address</name > <value > 10.10.20.40:8033</value > </property > <property > <name > yarn.resourcemanager.resource-tracker.address</name > <value > 10.10.20.40:8031</value > </property > <property > <name > yarn.resourcemanager.webapp.address</name > <value > 10.10.20.40:8088</value > </property > </configuration >
配置说明:
10.10.20.40需要替换为你的hadoop主节点地址
配置workers文件:
在workers 文件中添加所有参与集群的DataNode域名或IP。
1 2 3 4 [hadoop@gis040 hadoop]$ vim workers 10.10 .20 .38 10.10 .20 .39 10.10 .20 .40
向节点服务器分发配置好的hadoop软件
1 2 [hadoop@gis040 hadoop]$ scp –r /home/hadoop-3.1 .1 root@10.10 .20 .38 : /home [hadoop@gis040 hadoop]$ scp –r /home/hadoop-3.1 .1 root@10.10 .20 .39 : /home
格式化namenode
在master节点上执行如下命令:
1 [hadoop@gis040 hadoop]$ ../../bin/hdfs namenode -format
启动Hadoop服务
1 2 [hadoop@gis040 hadoop]$ cd ../.. [hadoop@gis040 hadoop-3.1 .1 ]$ sbin/start-all.sh
hdfs中创建hive所需目录
格式化成功后,在hdfs中创建hive需要的目录,并分配权限
1 2 3 4 [hadoop@gis040 hadoop-3.1 .1 ]$ hadoop fs -mkdir /tmp [hadoop@gis040 hadoop-3.1 .1 ]$ hadoop fs -mkdir -p /user/hive/warehouse [hadoop@gis040 hadoop-3.1 .1 ]$ hadoop fs -chmod g+w /tmp [hadoop@gis040 hadoop-3.1 .1 ]$ hadoop fs -chmod g+w /user/hive/warehouse
部署mysql80 for CentOS7
部署mysql Server
检测是否存在之前安装的版本:
1 2 3 [root@gis040 ~] # rpm -qa |grep mysql [root@gis040 ~] # rpm -e mysql (如果存在历史版本则执行该语句删除)[root@gis040 ~]# rpm -e —nodeps mysql (强制删除)
安装mysql server:
由于CentOS7版本中的MySQL数据库已经从默认的程序列表中删除,所以安装前先去下载资源包。
下载地址:https://dev.mysql.com/downloads/repo/yum/
包名:mysql80-community-release-el7-1.noarch.rpm
1 2 3 4 [root@gis040 ~]# wget http://repo.mysql.com/mysql80-community-release-el7-1.noarch.rpm [root@gis040 ~]# rpm -ivh mysql80-community-release-el7-1.noarch.rpm [root@gis040 ~]# yum update [root@gis040 ~]# yum install mysql-community-server
启动MySQL服务器:
1 [root@gis040 ~]# systemctl start mysqld
查看MySQL运行状态:
1 [root@gis040 ~]# systemctl status mysqld
验证MySQL是否工作正常
1 2 [root@gis040 ~]# mysqladmin —version mysqladmin Ver 8.0.12 for Linux on x86_64 (MySQL Community Server - GPL)
如果能正确显示版本信息,则说明安装成功。
配置root用户
修改root用户密码:
安装完第一次启动时,mysql会为root用户设置一个随机密码,可以通过下面命令修改:
1 2 [root@gis040 ~]# grep “password” /var/log/mysqld.log 2018-10-16T01:45:10.838489Z 5 Note [Server] A temporary password is generated for root@localhost: 9-UdH*>ljxu<
使用查询出的密码登陆mysql:
1 [root@gis040 ~]# mysql -u root -p
登陆后重新设定root用户密码:
1 mysql> set password ="Test@123" ;
更改root加密方式:
从mysql8.0开始,初始化数据目录时,root账户默认使用caching_sha2_password加密 ,hive的配置要求使用mysql_native_password,可以通过以下命令更改:
1 mysql> alter user 'root' @'localhost' identified with mysql_native_password by 'Test@123' ;
开启root用户的远程访问权限:
1 mysql> update user set host = '%' where user = 'root ';
验证修改结果:
1 2 3 4 5 6 7 8 9 10 mysql> select host,user from user; +-----------+ ------------------+| host | user | +-----------+ ------------------+| % | root | | localhost | mysql.infoschema | | localhost | mysql.session | | localhost | mysql.sys | +-----------+ ------------------+4 rows in set (0.01 sec)
创建要配置被hive使用的用户
1 2 3 mysql> create user 'hive' identified by 'Hive@123' ; mysql> grant all on *.* to 'hive' @'%' with grant option; mysql> flush privileges;
修改my.cnf,配置MySQL字符编码和端口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@gis040 ~]# vim /etc/my.cnf [mysqld] port = 3306 datadir =/var/lib/mysqlsocket =/var/lib/mysql/mysql.socklog-error =/var/log/mysqld.logpid-file =/var/run/mysqld/mysqld.pidinit_connect ='SET collation_connection = utf8_unicode_ci' init_connect ='SET NAMES utf8' character-set-server =utf8collation-server =utf8_unicode_ciskip-character-set-client-handshake
修改后重启服务:
1 [root@gis040 ~]# systemctl restart mysqld
部署MySQL Connector
提前下载好对应于mysql server版本的connector rpm, 切记版本一定要一致。
下载地址:https://dev.mysql.com/downloads/connector/j/
这里使用的是: mysql-connector-java-8.0.12-1.el7.noarch.rpm
1 [root@gis040 ~]# yum localinstall /home/soft/mysql-connector-java-8.0 .12 -1. el7.noarch.rpm
安装后,定位到connector jar 包 mysql-connector-java-8.0.12.jar,在Centos7系统上位于/usr/share/java目录下。
部署hive
部署hive安装包
从官网下载hive 3.1.0版本:
下载地址:http://mirrors.hust.edu.cn/apache/hive/hive-3.1.0/
创建安装用户hive:
1 2 [root@gis040 ~]# adduser hive [root@gis040 ~]# passwd hive
拷贝介质,修改所有权,解压缩:
1 2 3 4 5 6 [root@gis040 ~] [root@gis040 ~] [root@gis040 ~] [hive@gis040 root]$ cd /home [hive@gis040 home]$ tar -zxvf apache-hive-3.1 .0 -bin.tar.gz [hive@gis040 home]$ mv apache-hive-3.1 .0 -bin hive-3.1 .0
配置环境变量
1 2 3 4 5 6 7 [hive@gis040 home]$ exit [root@gis040 ~]# vim /etc/profile export HIVE_HOME =/home/hive-3.1.0export PATH =$PATH :$HIVE_HOME/bin[root@gis040 ~]# source /etc/profile
配置hive-env文件:
1 2 3 4 5 6 7 [hive@gis040 root]$ cd /home/hive-3.1 .0 /conf [hive@gis040 conf]$ cp hive-env.sh.template [hive@gis040 conf]$ vim hive-env.sh 配置两个变量: HADOOP_HOME=/home/hadoop -3.1 .1 export HIVE_CONF_DIR=/home/hive /hive-3.1.0/conf
配置hive-site.xml:
拷贝配置文件,命名为hive-site.xml
1 [hive@gis040 conf]$ cp hive-default .xml.template hive-site.xml
配置修改以下项目:
修改xml中的特殊字符错误:
1 2 [hive@gis040 conf]$ vim +3210 hive-site.xml 删除 “&
配置mysql连接参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [hive@gis040 conf]$ vim +583 hive-site.xml 修改以下配置中的value值 <property> <name>javax.jdo .option .ConnectionURL </name> <value>jdbc:mysql: <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql: </description> </property> [hive@gis040 conf]$ vim +1100 hive-site.xml <property> <name>javax.jdo .option .ConnectionDriverName </name> <value>com.mysql .cj .jdbc .Driver </value> <description>Driver class name for a JDBC metastore</description> </property> [hive@gis040 conf]$ vim +1126 hive-site.xml <property> <name>javax.jdo .option .ConnectionUserName </name> <value>hive</value> <description>Username to use against metastore database</description> </property> [hive@gis040 conf]$ vim +568 hive-site.xml <property> <name>javax.jdo .option .ConnectionPassword </name> <value>Esri@123 </value> <description>password to use against metastore database</description> </property>
配置临时变量参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [hive@gis040 conf]$ vim +17 hive-site.xml 在<configuration> 标签后面添加下面的变量 <property> <name> system:java.io.tmpdir</name> <value> /home/ hive/tmp</value> </property> <property> <name> system:user.name</name> <value> hive</value> </property> <property> <name> mysql.ip</name> <value> 10.10 .20 .40 </value> </property> <property> <name> mysql.port</name> <value> 3306 </value> </property>
配置说明:
mysql.ip 替换成实际你配置中的mysql Server的IP
mysql.port 默认是3306, 应遵从之前my.cnf中的配置
system:java:io:tmpdir目录需要替换成你的临时目录,如果没有通过以下命令创建
1 [hive@gis040 conf]$mkdir -p /home/hive/tmp
拷贝mysql 的connector jar包到hive lib目录下
1 2 3 4 [hive@gis040 conf]$ exit [root@gis040 ~] [root@gis040 ~] [root@gis040 lib ]
1 2 [root@gis040 lib ] [root@gis040 lib ]
启动服务
启动thrift server , 默认端口:10000
检查端口是否已启动:
1 2 3 4 5 [hive@gis040 lib ]$ netstat -nl |grep 9083 tcp6 0 0 :::9083 :::* LISTEN [hive@gis040 lib ]$ netstat -nl |grep 10000 tcp6 0 0 :::10000 :::* LISTEN
beeline测试thrift 接口是否能连通
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [hive@gis 040 lib]$ beeline -u jdbc: hive2: 0 : jdbc: hive2: > create table bjRain(ID string,X double ,Y double ,STATIONNAM string) > row format delimited fields terminated by ',' > stored as textfile; 0 : jdbc: hive2: > create table bjRain(ID string,X double ,Y double ,STATIONNAM string) > row format delimited fields terminated by ',' > stored as textfile; 0 : jdbc: hive2: > load data local inpath '/home/soft/bjRAINSub.csv' overwrite into table bjRain; 0 : jdbc: hive2:
为ArcGIS GeoAnalytics注册hive数据源
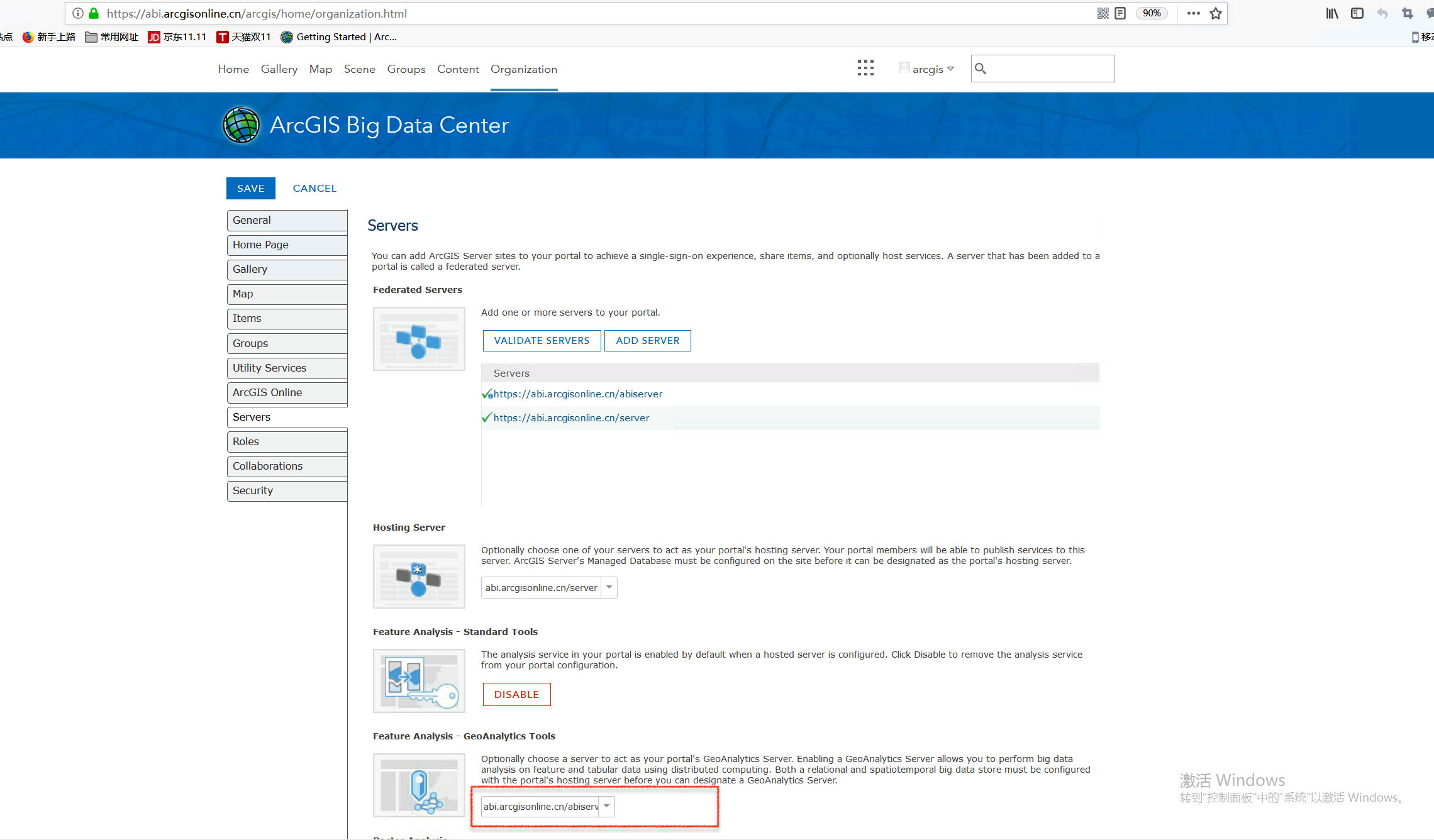
获取注册为GA 的Server地址
在ArcGIS Enterpris的Organization - Edit settings - Server中查看注册为GA的ArcGIS Server地址。
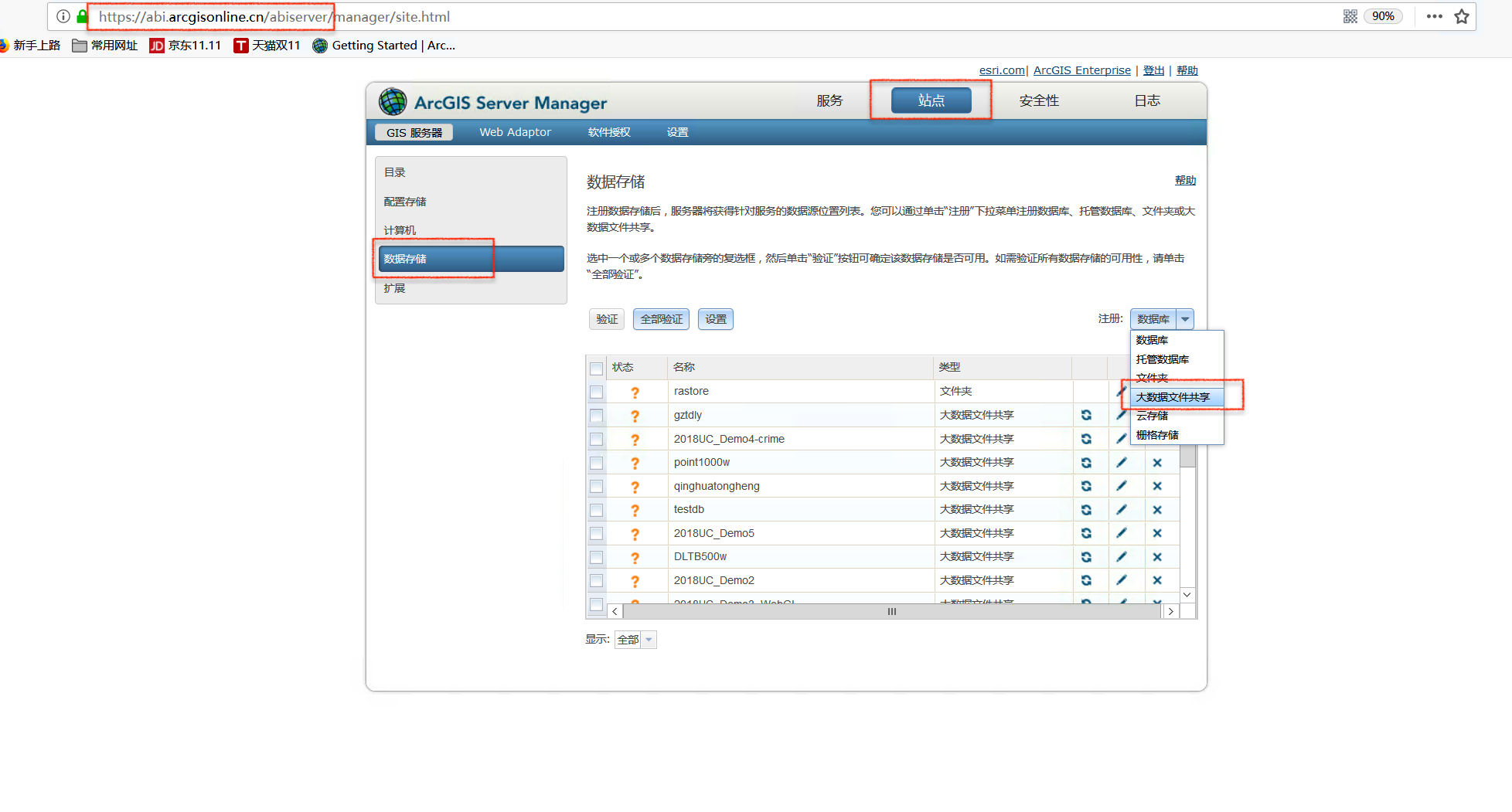
导航至注册窗口
进入作为GA Server 的ArcGIS Server Manager,导航至站点-> 数据存储, 在注册数据库的下拉列表中选择“大数据文件共享”。
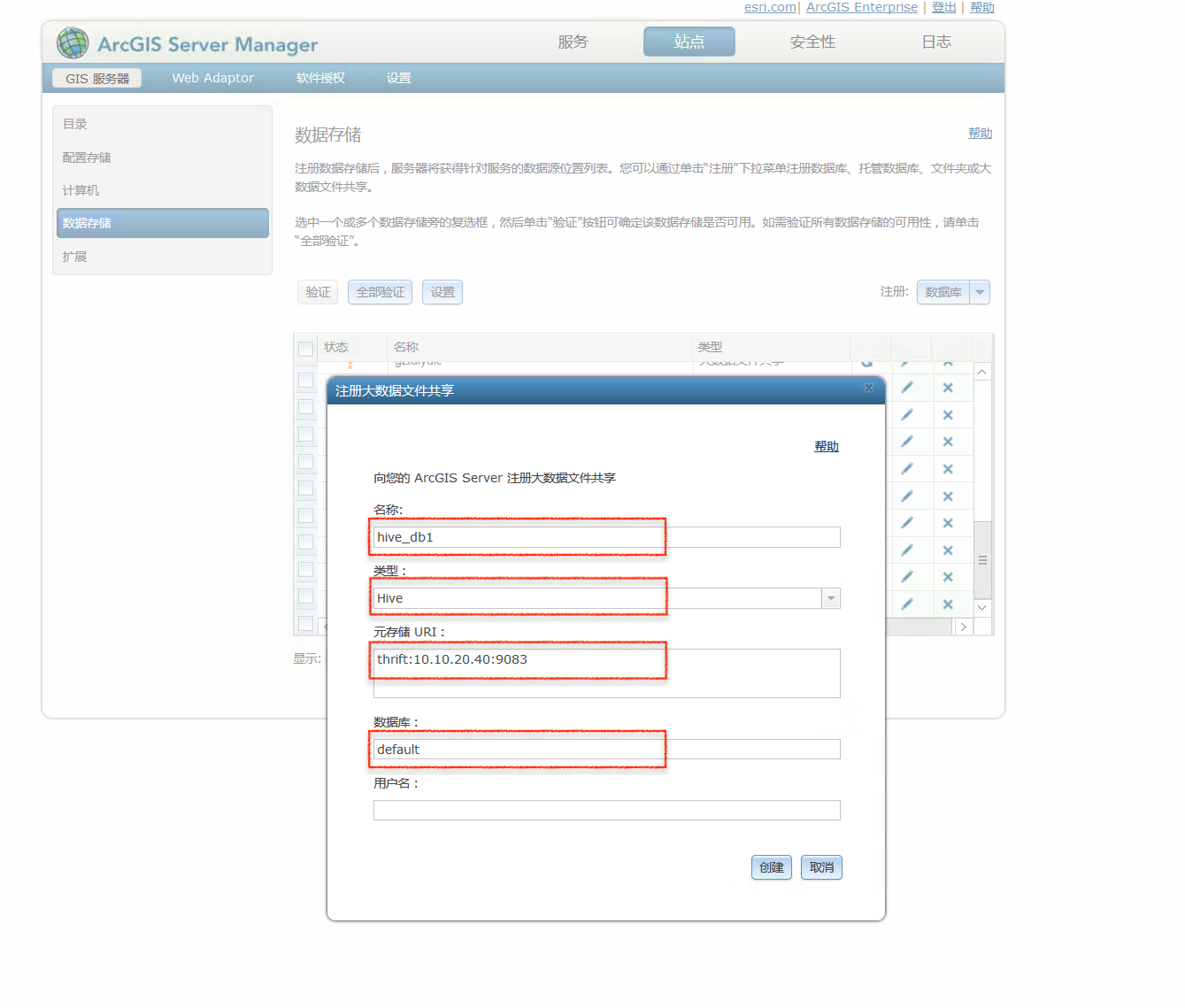
配置注册参数
在弹出的配置窗口中,输入以下参数值:
注册参数:
1 2 3 4 name: hive_db1type: Hivemetastore URI: thrift: datastore: default
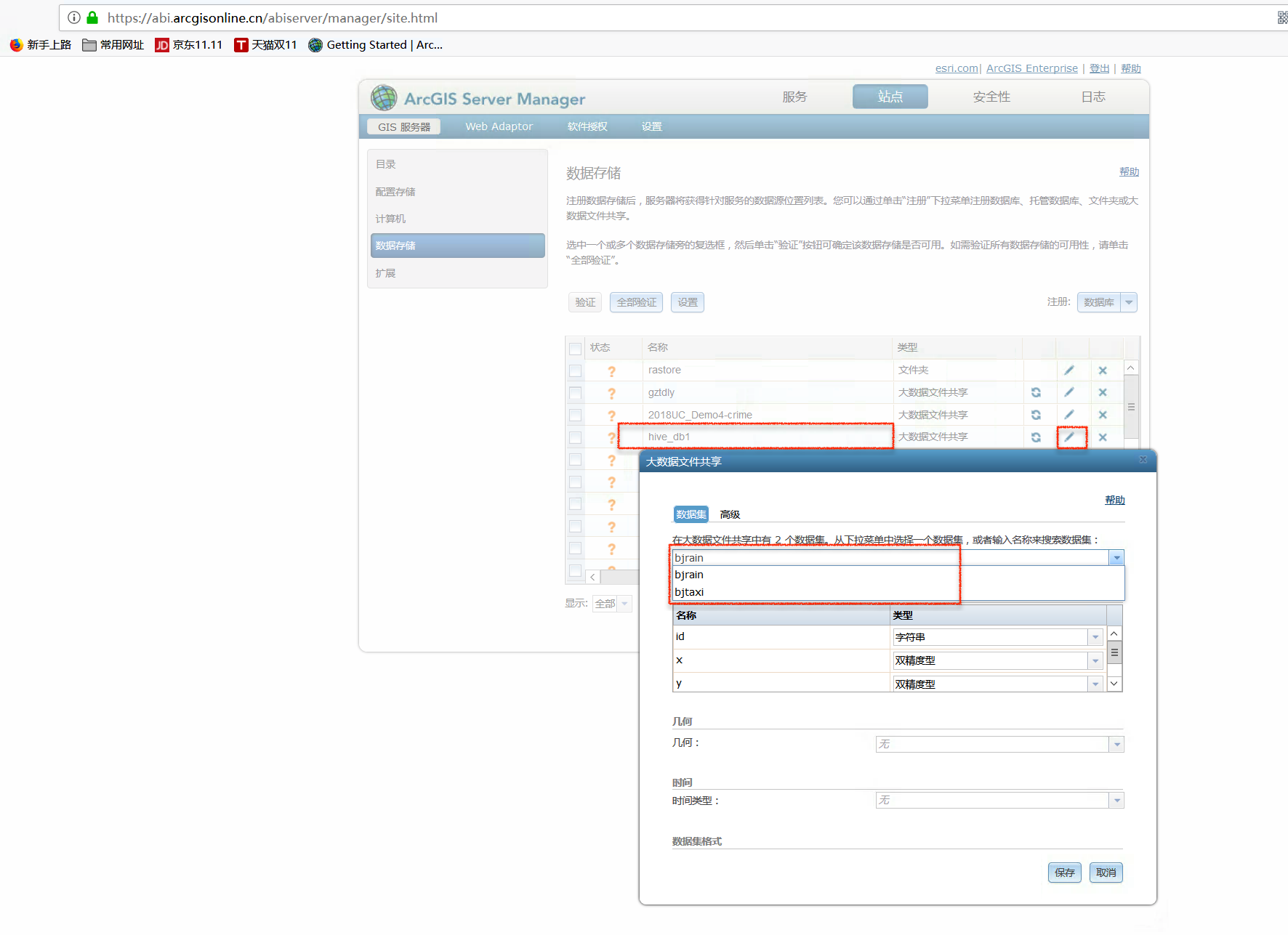
验证成果
成功注册后,可以通过编辑按钮查看注册的大数据信息。