聚类,分组和分类技术一直是机器学习中使用最广泛的一些方法。在机器学习、人工智能技术铺天盖地涌入的今天,除了AI专家,普通人可能也对这些算法名称略有了解,比如K-mean分类算法。今天要跟大家分享的这个工具就跟聚类有关,它是ArcGIS 10.6.1版本中GA新增加的一个空间模式识别工具——基于密度的点聚类分析,事实上在当前时间节点10.6.1尚未正式发布,这篇文章算是提前剧透了:)
聚类是帮助我们发现事件或对象空间分布规律的非常有用的方法,比如通过分析管道破裂或爆裂的集中区域可以指明隐藏在地下的城市供水网络潜在的问题,找到这些聚类的位置,就可以对高危区域抢先采取行动。再比如假设我们想优化篮球队的战略战术,那可以采集队员投篮成功和失败的所有位置数据,基于密度聚类,可以获得每位球员成功和失败投篮位置的不同模式,这个信息就可以进一步的用来优化比赛战术。这些分析都可以使用今天要介绍的基于空间密度的点聚类工具。
功能定义
这个工具的核心功能是检测点数据集中集聚区域和被空的或稀疏区域所分隔的区域。这个工具使用了非监督的机器学习聚类算法,这个算法并不需要预先针对聚类进行训练,仅根据空间位置和到指定邻域的距离通过最小聚类点数作为约束自动检测模式。详细的算法原理请参阅后面的原理分析部分。
使用工具
可能大家一听到“非监督机器学习”,瞬间就会觉得这是个很难使用的工具,事实上这个工具恰恰非常简单易用,输入,输出都很明确,也非常易于理解。
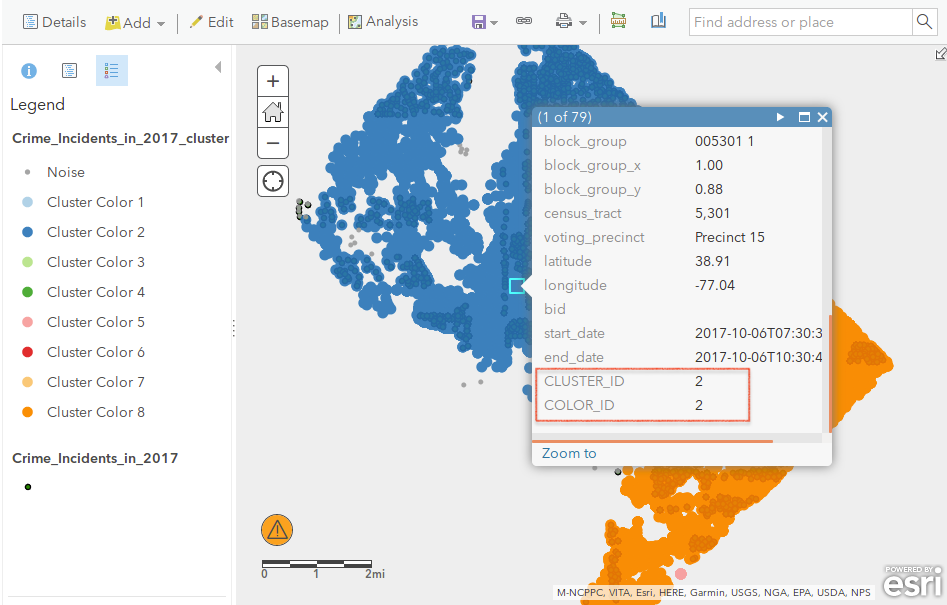
输入参数
- 设置点图层,在大数据分析工具中,这个点图层的空间参考要求是投影坐标系的,如果数据本身不是,那可以通过设置环境变量中的工具处理空间参考为投影坐标系,比如3857,来实现动态投影;
- 设置最小点数,这个值可以理解为最少多少个点可以被考虑为一个聚类,分析区内如果点数低于这个值,说明密度低于临界值,过于稀疏,反之,这些点可以组成一个聚类;
- 设置搜索半径,这个值用于创建分析邻域,以分析点为中心,这个值为半径,就可以缓冲一个圆,这个圆就可以用来判断中心点是否属于哪个聚类或是噪点;
- 设置输出图层名;
- 选择是否仅分析当前地图范围的要素。
分析过程
从输入参数和输出结果来判断,GA工具中的点聚类工具,后面对应的算法应该是DBSCAN, 后面我还会细说这个算法,在这儿先大概描述下工具背后执行的逻辑:
- 针对待分析点先按照搜索半径生成缓冲区;
- 查询缓冲区范围内覆盖的点;
- 如果点数> 最小点数,就标识中心点属于某个聚类ID,然后再针对上面搜索到的点执行buffer创建,根据判断条件标识聚类ID;
- 如果点数< 最小点数,就标识为噪点,重新跳回起点,分析下一个点;
按照上面的循环迭代下来,每个点都会被判断为属于某个聚类,或者是噪点。
输出结果
这个工具的执行,输出结果非常明确,所有点要素会被区分为噪点或者某一聚类,至于结果输出多少类,完全取决于算法对数据的探索,当然约束条件就是搜索半径和最小点数。
-
输出结果图层和输入点层的记录数完全一致
-
输出结果图层会增加CLUSTER_ID, COLOR_ID两个新字段,一个代表分类,一个代表渲染ID。为何不直接使用CLUSTER_ID作为渲染字段?因为如果输出的聚类过多,使用过多的颜色渲染,反而会降低辨识度,因此默认最大选择8种颜色来循环渲染聚类,噪点使用灰色的小点来单独表达。
原理分析
基于密度的点聚类分析,在ArcGIS Pro中也有对等的工具,并且支持三种算法:
- DBSCAN(Density-based spatial clustering of applications with noise): 使用指定距离将密集聚类与稀疏噪点分离。DBSCAN 算法是最快的聚类方法,但仅适用于要使用的搜索距离非常明确,并且非常适用于所有潜在聚类的情况。这要求所有有意义的聚类密度相似。
- HDBSCAN(Hierarchy DBSCAN): 使用一系列距离将不同密度的聚类与稀疏噪点分离。HDBSCAN 算法是最以数据为驱动的聚类方法,因此需要的用户输入最少。
- OPTICS(Ordering points to identify the clustering structure): 使用相邻要素之间的距离创建可达图,随后使用此可达图将不同密度的聚类与噪点分离。OPTICS 算法在优化检测到的聚类方面最为灵活,但其属于计算密集型,尤其是当搜索距离较大时。
对于大数据分析来说,速度显然是非常重要的指标,通过将GA中点密度生成结果和Pro中基于三种算法生成的结果一一对比,确认GA中使用了速度最快的DBSCAN的算法,因此这篇文章我只针对DBSCAN算法原理进行详细的分析,如果对其它算法感兴趣,可以移步直接学习Esri的官方帮助文档,里面讲解的也非常生动详细。
算法原理
DBSCAN 于1996年由Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu四个人最早提出, 核心的思想是通过计算邻域内点的密度,将距离近的点组成类,密度稀疏的点标注为噪点。DBSCAN可以说是最常用高效的聚类算法。
这个算法的核心输入是两个约束:
- 最小聚类点数
- 搜索距离
DBSCAN会针对要素点集合中的每个点(判断目标点或核心点),根据搜索距离创建一个邻域,对于GISer来说可以想象针对一个点按照搜索距离创建一个buffer, 通过这个buffer可以搜索出落入的所有点要素.,进一步就可以计算出这个邻域密度:
coreP_density = 邻域内点数(包含中心点)/ 邻域面积
如何判断这个密度是稠密还是稀疏?显然还需要一个判断标准,这个标准就取决于最小点数密度:
minP_density = 最小点数 / 邻域面积
注意: 这个minP_density实际是个常数,因为对于DBSCAN算法来说,邻域面积都是相同的,最小点数也是固定的。
DBSCAN的核心思想就是比较这两个密度,如果核心点所在邻域的密度>临界密度,就创建聚类,或分配到某个已经存在的聚类,反之就标注为稀疏点。对于算法程序来说,有个取巧的办法,既然邻域面积相同,事实上直接比较点数就可以了,这样计算更快。
再通过下面的图,直观的来理解下DBSCAN聚类的方法:
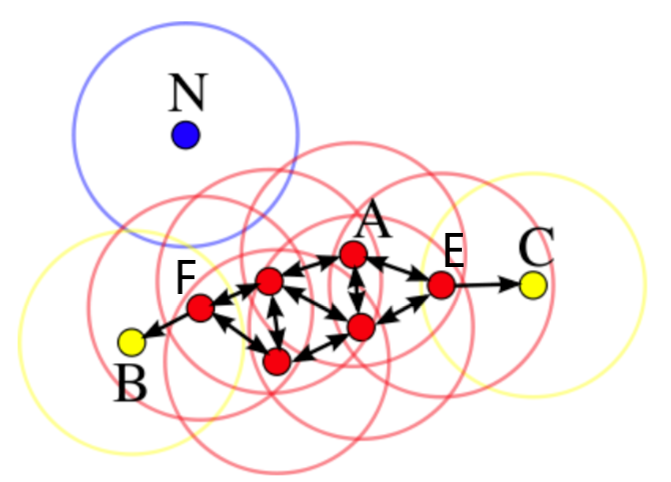
在这个例子中,最小点数为4,圆环代表邻域:
- 假设A点是我们选取的随机起算点,那么以A点为中心,邻域距离为半径绘制的缓冲区中,包含了4个点,这个区域的密度超过最小临界密度,可以构成一个聚类。然后依次判断邻域内的其它三个点,以每个点为中心,绘制缓冲区,再判断每个区域的密度,上图中A点到它邻域内的其它三个点均相互可达,他们属于同一个聚类。按照这样的规则,想像不断生长的密度气泡,就可以把空间距离较近的点链接起来,形成密度区,图中红色点代表相互可达的核心点,属于同一个聚类。
- B和C点为黄色, 它们是边界点,聚类中的E点到C点可达,说明C点离该聚类不远,归属该聚类,但是以C点为核心,邻域内的点数仅为1,已经低于临界密度,所以C点又是个边界点,意味着C之外的点需要开启新的聚类或者因为过于稀疏,成为噪点。
- 再来看蓝色N点,以N点为中心,邻域内没有其它的点到N点可达,从N点也无法到达任何点,说明N点所在区域密度过于稀疏,该点标识为噪点。
以上就是DBSCAN的算法原理,对于程序猿来说可能还是直接看实现代码更畅快些,下面的伪代码来自维基,非常非常清晰的表达出DBSCAN的整个算法实现过程。
1 | DBSCAN(DB, distFunc, eps, minPts) { |
声明:上述代码和GA中工具实现的逻辑完全无关。
优劣分析
优势
- DBSCAN 不需要像k-means一样预先指定数据分多少类;
- DBSCAN可以发现任何形状的聚类,甚至会发现完全被其它聚类围绕的聚类。由于MinPts参数的作用,单链效应的情况极大的减少了;
- DBSCAN只需要两个参数,对于数据集中点的顺序不敏感;
- DBSCAN可以使用数据库的空间索引加速查询,因此非常高效;
劣势
- 参数minPts和邻域距离,需要由对数据理解良好的领域专家来设置;
- 采用统一的密度标准来衡量,这就要求所有有意义的聚类密度相似。
了解了这个工具的算法,大家是否会觉得原来机器学习没那么高深?竟然如此简单?分分钟就完成个大数据聚类运算?其实真正的难点并不是理解工具运算原理和如何使用工具,关键点在于对待分析数据和要解决问题的理解,然后才能给出合适的最小聚类点数和邻域距离,而这些参数直接决定了分类结果。说到这儿,想起之前看到过的一个笑话:
一次,福特公司里一台大型电机发生了故障,工程师们会诊3个月没有结果,只得请来权威斯坦门茨。这位权威及时挽救了电机,而有人却嫉妒地说斯坦门茨向公司要1万美元,这1万美元是不是勒索呢?斯坦门茨写在付款单上的说明就是最好的回答:“画一条线=1美元,知道在什么地方画线=9999美元。
参考资料
ArcGIS help: “基于密度的聚类” 工作原理
Wiki:DBSCAN