今天,我们已经实实在在的生活在大数据时代,每个人通过我们的日常活动几乎实时,以各种途径向云端贡献着数据,对海量数据的挖掘和运用,成为社会经济增长和智能管理的重要手段。今天的海量数据和10年前或者5年前的海量数据在量级上已经有所不同,一直以来我们可能更习惯通过查询、搜索过滤数据,今天我们依然在百度和谷歌上如此获得信息,这样做的结果是我们通过分析每条返回数据来获取知识。大数据时代我们面对的困难是什么?随着数据量级从GB级,升级到TB级,再过渡到PB级,通过搜索返回指定的记录(可能是几十万条),然后再针对这些记录进行分析,变得越来越难,即使技术上可以实现海量数据的搜索,针对返回的过多冗余数据,我们几乎也难以从中捕获到有价值的信息规律。我们真的关心每天收集的数据洪流中的每一条数据吗?在大数据时代,可能我们会说No,我们真正关心的是海量数据背后所呈现的潜在规律。当然,我不是说搜索不再重要了,只是在面对大数据时,在搜索前,可能需要首先对海量数据进行处理,比如将它们按一定模式聚合,聚合到可搜索、可分析的程度。
对于GIS我们关心任何人、事、物在地理空间上所呈现的规律性。对海量离散空间点数据,我们很容易想到,按照一定区域将它们聚合起来,这可以有效缩减数据量,让它们重新回归到可分析的尺度。相信ArcGIS的地理科学家们也是沿着这条思路设计了ArcGIS地理大数据解决方案,这篇文章就跟大家分享,可以实现海量点数据在空间区域聚合的工具——聚合点工具。
功能定义
聚合点工具在功能设计上非常简单,就是汇总落入区域面内的点,并计算点的个数、属性字段值的总和、最小值、最大值、均值、方差、和标准差等统计数据。你可能会问,统计这些有什么用呢?事实上是非常有用,通过统计数据让我们关注的层次从个体提升到了区域整体,可以洞察到更深刻的规律,而免去渲染海量数据的苦恼。在这里落入每个区的:
-点个数:可以直观地通过地图看出样本点在每个区域分布的规律;
-总和:反映了每个区域特征总值,通过地图仍然可以直观看出特征值在每个区域上的分布情况;
-最小值,最大值:反映了区域内特征值的分布域值;
-均值:反应每个区域的样本特征期望,更多情况下均值相对总和更能反应问题;
-方差,标准差:反映了样本的松散度,松散度可以理解为特征值偏离均值的程度。
关于这些统计值的计算方法,可以参阅我之前写的文章:《空间分析的数学基础》
使用工具
聚合点工具虽然很简单,但却是我们进行大数据分析必备的工具。正如这个工具名所代表的含义,它是设计用来聚合点的工具(GISer往往有这种偏执,为何它不支持聚合线和面?),所以输入限定只支持汇聚点图层。
接下来我们看看这个工具如何使用。
输入参数
聚合点工具是用来计算落入区域内的点要素的各种统计指标,很容易想到最核心的收入参数就是一个面图层和一个点图层。这个面我在这里称为“区域图层”,因为它实际代表了汇聚统计结果的小区图层。以下详细介绍下各输入参数:
- 输入大数据点图层
这个图层中的点代表了包含特征值的事件点。 - 设置区域图层
区域图层有两种选择:- 输入一个行政区划或人为规划的面图层(比如网格管理中的格网)
- 选择由工具自动生成格网,这里支持六边形和四边形,这种方式我们只要指定格网高度d就可以了,格网生成规则遵循:

-
(可选)设置时间步长
如果输入的点图层开启了时态,并且时间是instant(时刻)类型,这个工具就支持使用时间步长来分析。时间参数可以通过:时间步长间隔、时间步长重复频率和起算时刻三个参数来控制。为了更好的理解设置时间步长的意义,想象输入的点图层中包含了一年收集的数据,如果我们想以周为单位分析,就可以设置时间步长间隔为1周。如果我们事实上只关心一年中每个月的第一周的统计数据,那可以进一步设置时间步长重复率为1个月。那从什么时刻开始统计呢?还需要设置最后一个参数起算时刻,如果这个参数省略,默认会从1970年1月1日开始。
-
(可选)设置统计字段和统计项
这是个可选项,我们可以有目标的指定某个属性字段参与统计,也可以不选,默认模式是全字段统计。
统计项针对数值型和字符串型有所不同:- 数值型:支持统计计数、总和、最小值、最大值、范围、平均值、标准差、方差统计项;
- 字符串型:支持计数(count)和任意(any)两个统计项,其中count会返回非空值的计数,any返回落入区域中任意点的统计字段属性值,实践证明这个值确实是随机选的。
-
设置结果图层名
-
如果区域图层使用自动生成四边形或六边形格网的方式,还需要设置空间参考为投影坐标系
-
选择是否使用当前图层范围
输出结果
聚合点工具执行的结果会生成全新的feature service, geometry会复制区域面中的要素,属性字段为各统计项。以下是分别采用自动生成格网和输入面多边形聚合的结果:
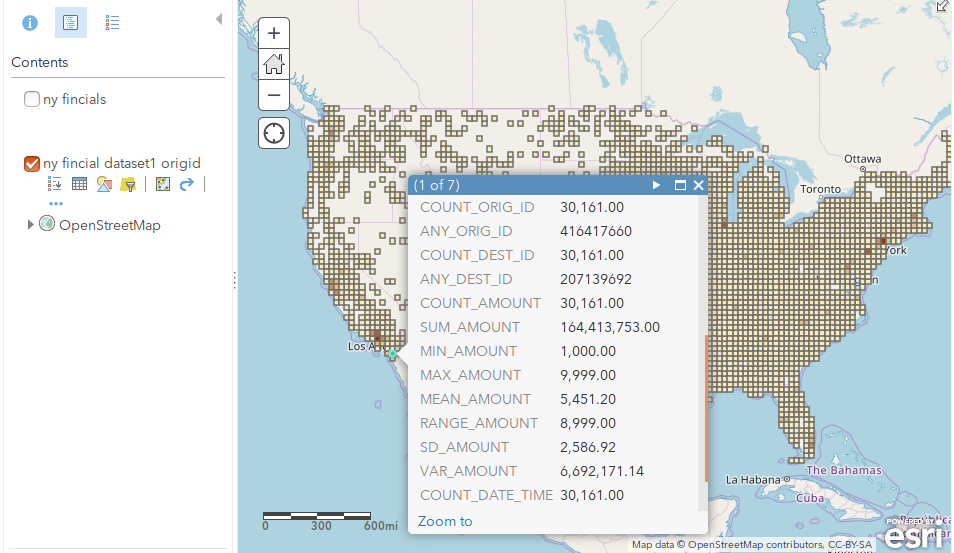
1 采用5km矩形格网,聚合美国2016年金融交易数据的分析结果
2 采用美国行政区划图,聚合每月第一周,2016年以来美国金融交易数据的分析结果
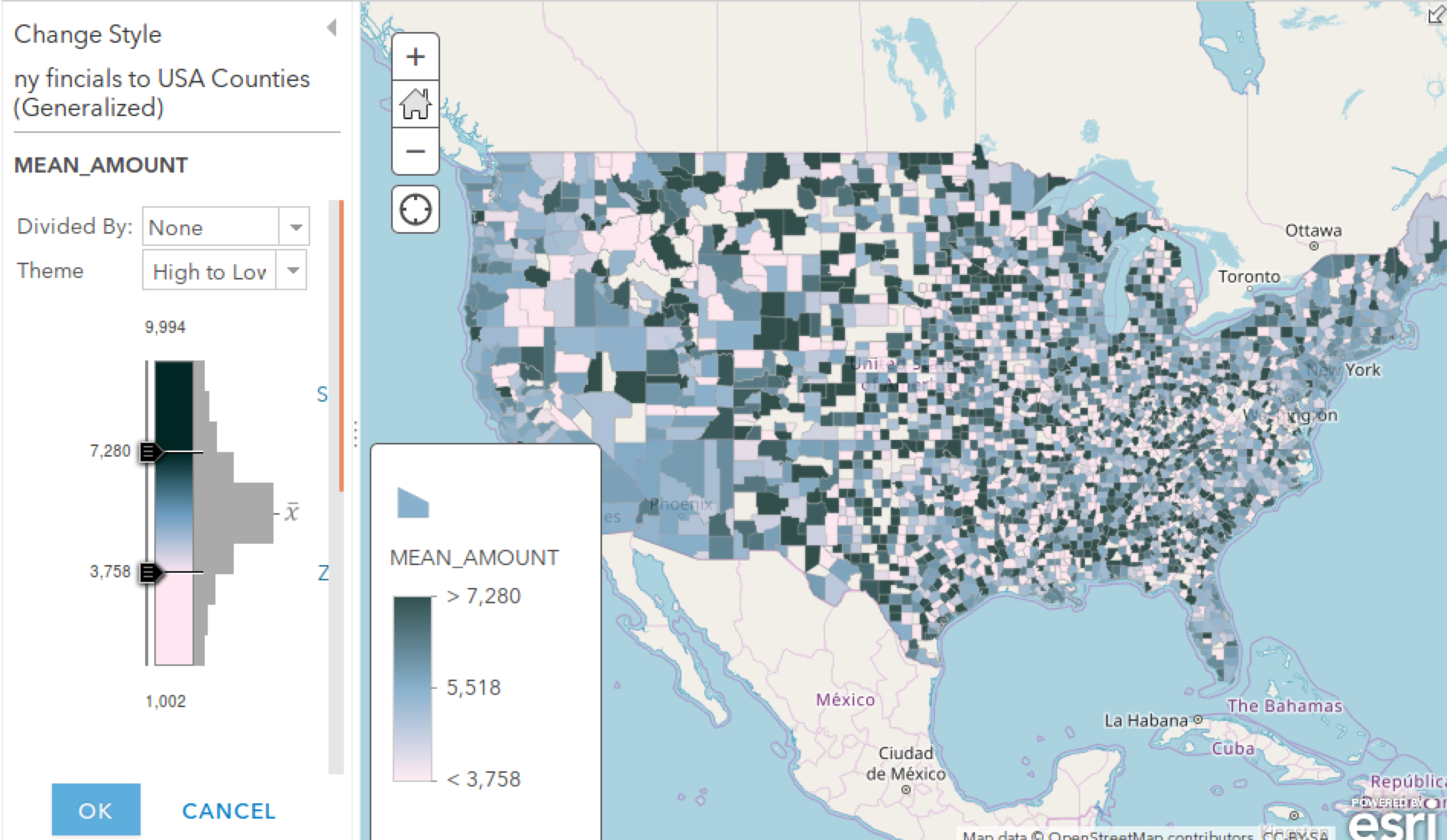
在这里渲染选择了按照交易均值(mean_amount)为渲染字段,3758和7280代表了两个标准差距离,概率大约为95%,聚合后通过这种在地图上的直观表达,我们的眼睛就能识别出整个美国金融交易的均值分布规律。
直觉上硅谷应该是当今世界的财富热区,这个聚合后的分析结果是否能反应出这点呢?接下来将地图缩放到硅谷所在的旧金山南部湾区一探究竟:
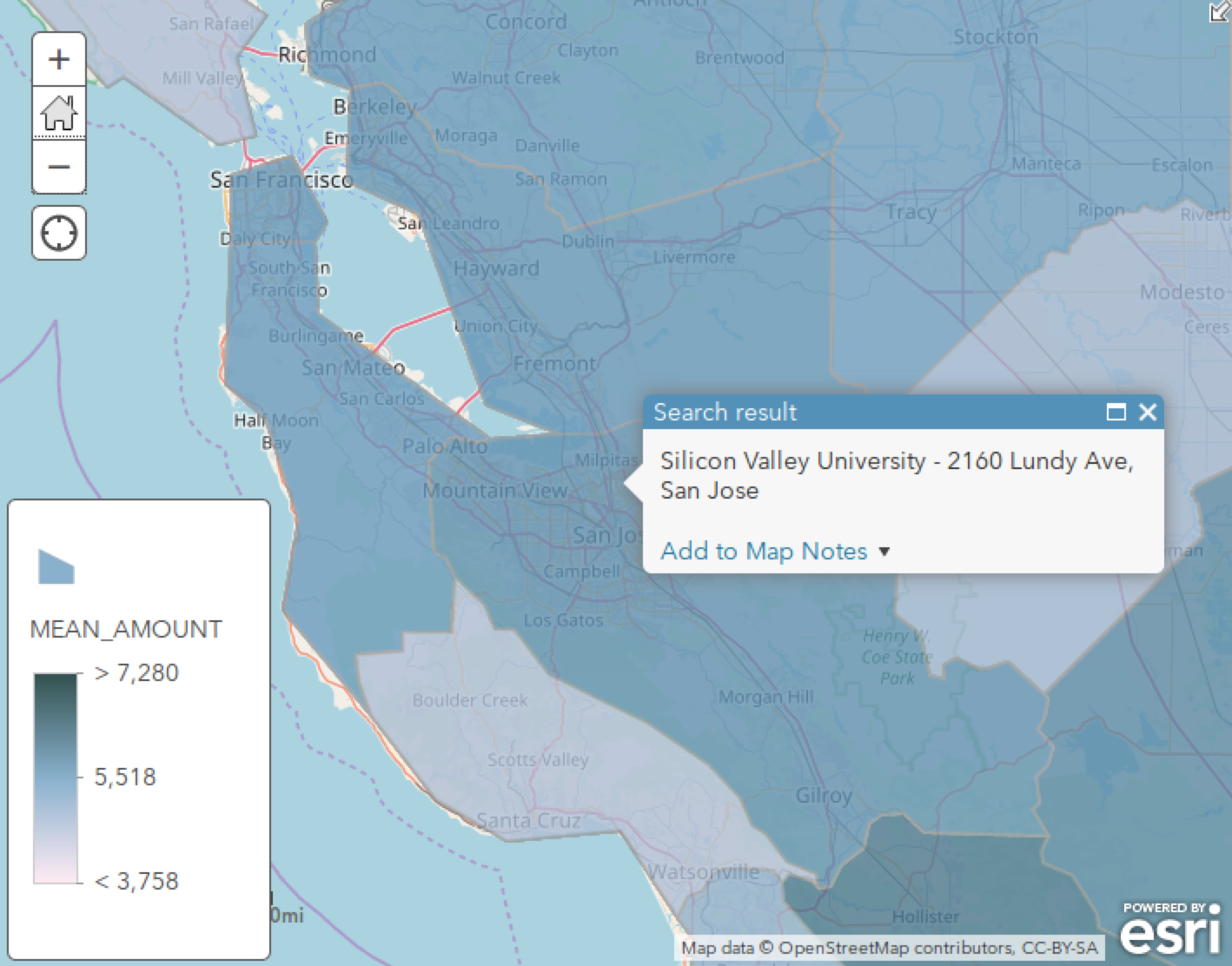
果然这一片区是妥妥的蓝色,交易均值偏高。
参考资料
- ArcGIS Help: 聚合点